
Direct-address table
If the keys are drawn from the reasoning small universe U = {0, 1, . . . , m-1} of keys, a solution is to use a Table T[0, . m-1], indexed by keys. To represent the dynamic set, we use an array, or direct-address table, denoted by T[0 . . m-1], in which each slot corresponds to a key in the universe.
Following figure illustrates the approach.
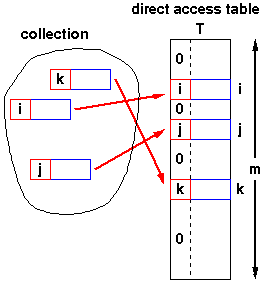
Each key in the universe U i.e., Collection, corresponds to an index in the table T[0 . . m-1]. Using this approach, all three basic operations (dictionary operations) take θ(1) in the worst case.
Hash Tables
When the size of the universe is much larger the same approach (direct address table) could still work in principle, but the size of the table would make it impractical. A solution is to map the keys onto a small range, using a function called a hash function. The resulting data structure is called hash table.
With direct addressing, an element with key k is stored in slot k. With hashing =, this same element is stored in slot h(k); that is we use a hash function h to compute the slot from the key. Hash function maps the universe U of keys into the slot of a hash table T[0 . . .m-1].
h: U → {0, 1, . . ., m-1}
More formally, suppose we want to store a set of size n in a table of size m. The ratio α = n/m is called a load factor, that is, the average number of elements stored in a Table. Assume we have a hash function h that maps each key k  U to an integer name h(k) [0 . . m-1]. The basic idea is to store key k in location T[h(k)].
U to an integer name h(k) [0 . . m-1]. The basic idea is to store key k in location T[h(k)].
U to an integer name h(k) [0 . . m-1]. The basic idea is to store key k in location T[h(k)].Typical, hash functions generate "random looking" valves. For example, the following function usually works well
h(k) = k mod m where m is a prime number.
Is there any point of the hash function? Yes, the point of the hash function is to reduce the range of array indices that need to be handled.
Collision(class between two numbers when the key is same)
As keys are inserted in the table, it is possible that two keys may hash to the same table slot. If the hash function distributes the elements uniformly over the table, the number of conclusions cannot be too large on the average, but the birthday paradox makes it very likely that there will be at least one collision, even for a lightly loaded table
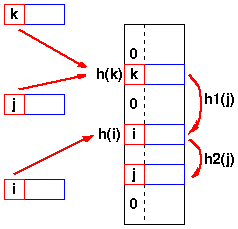
A hash function h map the keys k and j to the same slot, so they collide.
There are two basic methods for handling collisions in a hash table: Chaining and Open addressing.
Collision Resolution by Chaining
Code
When there is a collision (keys hash to the same slot), the incoming keys is stored in an overflow area and the corresponding record is appeared at the end of the linked list.
When there is a collision (keys hash to the same slot), the incoming keys is stored in an overflow area and the corresponding record is appeared at the end of the linked list.
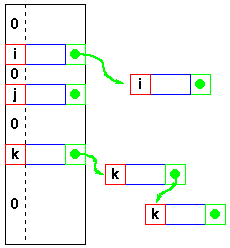
Each slot T[j] contains a linked list of all the keys whose hash value is j. For example, h(k1) = h(kn) and h(k5) = h(k2) = h(k7).
slot, creating a list of length n. The worst-case time for search is thus θ(n) plus the time to compute the hash function.
keys: 5, 28, 19, 15, 20, 33, 12, 17, 10
slots: 9
hash function = h(k) = k mod 9
slots: 9
hash function = h(k) = k mod 9
h(5) = 5 mod 9 = 4
h(28) = 28 mod 9 = 1
h(19) = 19 mod 9 = 1
h(15) = 15 mod 9 = 6
h(20) = 20 mod 9 = 2
h(33) = 33 mod 9 = 6
h(12) = 12mod 9 = 3
h(17) = 17 mod 9 = 8
h(10) = 10 mod 9 = 1
Figure
A good hash function satisfies the assumption of simple uniform hashing, each element is equally likely to hash into any of the m slots, independently of where any other element has hash to. But usually it is not possible to check this condition because one rarely knows the probability distribution according to which the keys are drawn.
In practice, we use heuristic techniques to create a hash function that perform well. One good approach is to derive the hash value in a way that is expected to be independent of any patterns that might exist in the data (division method).
Most hash function assume that the universe of keys is the set of natural numbers. Thus, its keys are not natural to interpret than as natural numbers.
Method for Creating Hash Function
- The division method.
- The multiplication method.
- Universal hashing.
1. The Division Method
Map a key k into one of m slots by taking the remainder of k divided by m. That is, the hash function is
h(k) = k mod m.
Example:
If table size m = 12
key k = 100
key k = 100
than
h(100) = 100 mod 12
= 4
h(100) = 100 mod 12
= 4
- Poor choices of m
- m should not be a power of 2, since if m = 2p, then h(k) is just the p lowest-order bits of k.
So, 2p may be a poor choice, because permuting the characters of k does not change value.- Good m choice of m
- A prime not too close to an exact of 2.
2. The Multiplication Method

Two step process
- Step 1:
- Multiply the key k by a constant 0< A < 1 and extract the fraction part of kA.
- Step 2:
- Multiply kA by m and take the floor of the result.
- The hash function using multiplication method is:
- h(k) = [m(kA mod 1)]
where "kA mod 1" means the fractional part of kA, that is, kA - [ kA ]
Advantage of this method is that the value of m is not critical and can be implemented on most computers.
- A reasonable value of constant A is
- A~= (sqrt5 - 1) /2=0.618033....
3. Universal Hashing
This involves choosing a hash function randomly in a way that is independent of the keys that are actually going to be stored. We select the hash function at random from a carefully designed class of functions.
Let table size m be prime. Decompose a key x into r +1 bytes. (i.e., characters or fixed-width binary strings). Thus

 by
by
=  {ha} can be shown to be universal. Note that it has mr + 1 members.
{ha} can be shown to be universal. Note that it has mr + 1 members.
This involves choosing a hash function randomly in a way that is independent of the keys that are actually going to be stored. We select the hash function at random from a carefully designed class of functions.
Let table size m be prime. Decompose a key x into r +1 bytes. (i.e., characters or fixed-width binary strings). Thus
x = (x0, x1,..., xr)
Assume that the maximum value of a byte to be less than m. Let a = (a0, a1,..., ar) denote a sequence of r + 1 elements chosen randomly from the set {0, 1,..., m - 1}. Define a hash function ha ha(x) =  aixi mod m
aixi mod m
With this definition, Open Addressing
This is another way to deal with collisions.
In this technique all elements are stored in the hash table itself. That is, each table entry contains either an element or NIL. When searching for element (or empty slot), we systematically examine slots until we found an element (or empty slot). There are no lists and no elements stored outside the table. That implies that table can completely "fill up"; the load factor α can never exceed 1.Advantage of this technique is that it avoids pointers (pointers need space too). Instead of chasing pointers, we compute the sequence of slots to be examined. To perform insertion, we successively examine or probe, the hash table until we find an empty slot. The sequence of slots probed "depends upon the key being inserted." To determine which slots to probe, the hash function includes the probe number as a second input. Thus, the hash function becomes
h:
and the probe sequence
< h(k, 0), h(k, 1), . . . , h(k, m-1) >
in which every slot is eventually considered.
Pseudo code for Insertion
HASH-INSERT (T, k)
i = 0
Repeat j <-- h(k, i)
if Y[j] = NIL
then T[j] = k
Return j
use i = i +1
until i = m
error "table overflow"
Repeat j <-- h(k, i)
if Y[j] = NIL
then T[j] = k
Return j
use i = i +1
until i = m
error "table overflow"
Pseudo code for Search
HASH-SEARCH (T, k)
i = 0
Repeat j <-- h(k, i)
if T[j] = k
then return j
i = i +1
until T[j] = NIL or i = m
Return NIL
Repeat j <-- h(k, i)
if T[j] = k
then return j
i = i +1
until T[j] = NIL or i = m
Return NIL
Following are the three techniques to compute the probe sequences.
- Linear probing.
- Quadratic probing.
- Double hashing.
These techniques guarantee that
< h(k, 0), h(k, 1), . . . , h(k, m-1) >
a permutation of < 0, 1, . . . , m-1> for each key k.
Uniform hashing required are not met. Since none of these techniques capable of generating more than m2 probe sequences (instead of m!).
Uniform Hashing
- Each key is equally likely to have any of the m! permutation of < 0, 1, . . . , m-1> as its probe sequence.
Note that uniform hashing generalizes the notion of simple uniform hashing.
1. Linear Probing
This method uses the hash function of the form:
h(k, i) = (h`(k) + i) mod m for i = 0, 1, 2, . . . , m-1
where h` is an auxiliary hash function. Linear probing suffers primary clustering problem.
2. Quadratic Probing
This method uses the hash function of the form
h(k, i) = (h`(k) + c1i + c2i2) mod m for i = 0, 1, 2, . . . , m-1
where h` is an auxiliary hash function. c1 + c2 ≠ 0 are auxiliary constants.
This method works much better than linear probing.
Quadratic probing suffers a milder form of clustering, called secondary clustering.
3. Double Hashing
This method produced the permutation that is very close to random. This method uses a hash function of the form
h(k, i) = (h, 9k) + ih2 (k)) mod m
where h1 and h2 are auxiliary hash functions.
The probe sequence here depends in two ways on the key k, the initial probe position and the offset.
No comments:
Post a Comment